For my final project in Digital Praxis Seminar Fall 2016, I compare my previous data project on feminism-related tweets in Korean with a similar project by Taylor et al.: Most characteristic words in pro- and anti-feminist tweets (2015). I will begin by briefly describing the two projects, then move on to compare the methodology employed in the two projects, then to a discussion.
The projects
During the recent few years, social media has become an important channel for activism, especially for campaigns and solidarity movements thanks to the medium’s virality that operates differently from traditional mass media’s gatekeeping process. This has been especially true of Twitter and feminism, where a series of hashtags over the years have spurred large and diverse discussion around the topic.
The trend of feminism on Twitter has also been an ongoing phenomenon in South Korea, a well-digitally connected (although somewhat encapsulated in a language barrier) and pervasively misogynic culture. I specifically looked at two collections of tweets: the first that amounts to roughly five thousand tweets contains #나는페미니스트입니다 (which translates to “hashtag I am a feminist”) and the second is a larger set of almost ninety thousand tweets that contain either “페미니스트” (“feminist”) or “페미니즘” (“feminism”). My rudimentary analysis shows that feminism-related tweets sharply increased in number around the same time as the hashtag’s introduction.
Taylor et al.’s project aims to “elucidate the differences in vocabulary that always happen around controversial topics,” in this case feminism. After collecting about one million tweets containing the terms ‘feminism,’ ‘feminist’ or ‘feminists,’ the team classified the tweets as “anti-feminist,” “pro-feminist” or “neither.” Then they analyzed the corpus for overrepresented terms, i.e. words that tend to appear in one category more often than in another. Their observations reveal some differences between pro-feminist tweets and anti-feminist tweets in terms of word usage.
Another project I will not discuss below but which is also relevant is Language and Gender in the Online Feminist Movement by Nora Goldman. This project involves an analysis “2.8 million tweets marked with either the “#yesallwomen” or “#notallmen” hashtag” in order to explore “what stylistic patterns emerge in feminism-related discourse” based on the speaker’s gender.
Comparison of methodology
Here I compare my data project’s approach with Taylor et al.’s, with a focus on data collection, data cleaning, and computational analysis.
Data Collection
My approach to scraping tweets was quite manual. I wanted to get a relatively small number of tweets that span over a long period of time (one year from the hashtag’s first appearance on Feb 10 2015). However, the Twitter API is restrictive when it comes to searching tweets older than a week or so. Therefore I chose to rely on Twitter’s web search interface which allows search from the beginning of the service. One thing about this interface is that only a small number of tweets appear at first; in order to see the rest, one has to scroll to the bottom of the page, which then makes the browser load more tweets. Moreover, the web browser will stop loading tweets once the number tweets loaded on the page goes above 3,200. In order to reduce the risk of not retrieving all existing tweets because of this caveat, I segmented my search by using the SINCE and UNTIL operators: this allowed me to search day by day, minimizing the tweets that each search will return. In the end I didn’t have to, because the number of tweets per day was not that big—but it served as a precautionary measure.
My Python script used the Selenium WebDriver, a tool that makes it possible to browse the internet without opening a visible browser window (it enables “headless” browsing). After visiting Twitter’s web search page URL followed by my search query, the script scrolls down to the bottom of the page, checks if by scrolling down more tweets were triggered to appear. Using the BeautifulSoup package, the script then saves the tweets and metadata parsed from the source HTML, iterating over each day. Afterwards I modified the same script to search for not the hashtag, but the terms “페미니즘” (feminism) or “페미니스트” (feminist). Once the script was set up, the scraping process took a few days with idle hours now and then.
In contrast, Taylor’s script makes use of the Twitter API, searching for 20 terms of which the last 100 tweets are randomly collected as much as the API limit allows for. This script resulted in a collection of 988,000 tweets containing “feminism”, “feminist” and/or “feminists” between January and April 2015. This seems reasonable because the aim for Taylor et al.’s project is not to capture the entirety of a specific movement in the past, but to look for general patterns in a broader, everyday usage. While my approach was much rougher, I think both of these approaches are justified in their goals; what matters in data collection is getting the data that matters, and depending on what data you want to get you must negotiate the tools.
Data Cleaning
Data cleaning involves a lot of things that happen between data collection and actual analysis. My process is not yet complete, as my original project is still a work in progress. One advantage of using the web search is that the search does not include retweets by default—which would require some cleaning in the case of the API, as mentioned below. In addition, after getting the tweets from the web, I did make use of the API to retrieve the full metadata based on the tweet ids. After making a somewhat full set of tweets, I exported another dataset which was stripped of everything except the year and month, in order to create visualize the change of tweet volume over time in R. Additionally, using Python’s re and codecs packages, I grabbed the text of each tweet cleaned the data of user handles and broken unicode; this part remains a work in progress, and is not included in the attached dataset files.
Taylor et al.’s process was much more comprehensive. Among the collected tweets, 1,000 were randomly chosen and manually labeled as pro-feminist, anti-feminist, neither, or other. These served as training data for a machine learning-based classification, which they state was a better classifier than sentiment analysis.
Also, in order to focus on tweets that people have actually written down, retweets and one-click shared links were removed, reducing the size of the dataset by nearly 60%. While it is a common approach to eliminate frequent stopwords in text analysis, the researchers chose to tokenize stopwords and most non-alphabetic characters; the basis of this decision was that tweets go up to only 140 characters, which could mean that small and frequent elements may be significant as well. (This is an interesting thing for me to consider, since 140 characters in Korean can convey much more information than 140 alphabets, which imposes a less strict choice of writing style. Experimentation and literature research could provide a guideline here.)
The process of Taylor et al.’s is actually a lot similar to what I would have liked to pursue; to experiment with NLP and machine learning techniques in order to explore my dataset. However, I have to point out that my design of the research was less thorough. The preparation of training data and cleaning in their project was conducted according to the next steps of analysis. By not having a concrete research question to start with, I had some data on my hand but what methods to apply for what type of analysis remained vague. Future work will address this problem (more on this below).
Analysis
After visualizing the number of tweets containing “페미니즘” or “페미니스트” over time, the increase in volume after the introduction of the hashtag #나는페미니스트입니다 was much obvious. I also experimented with NLP tools by counting term frequencies in the whole corpus of tweets with the hashtag, but without much result to share.
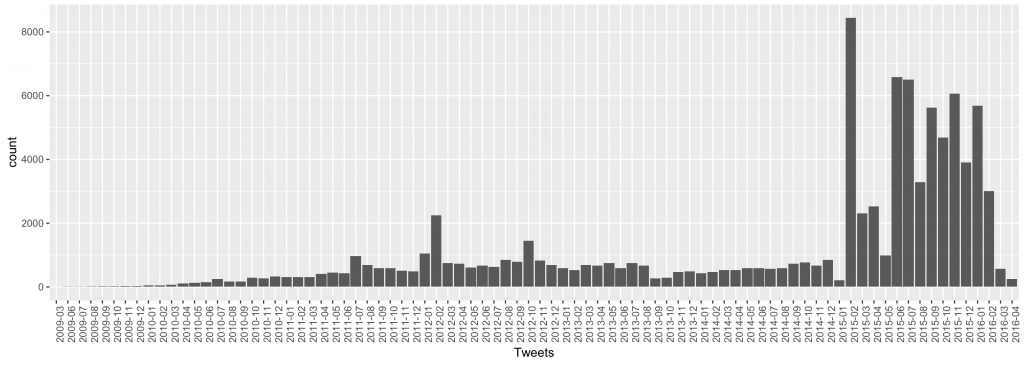
Taylor et al. classified the cleaned 390,000 tweets as pro- or anti-feminist based on the training set of 1,000 tweets. They represented each tweet as bags-of-words and used a Naive Bayes classifier, which showed 40% overall accuracy and about 60% false-positive rate (they “weren’t getting a lot of misclassifications inside two classes of interest, pro- and anti-“). Afterwards they “calculated the log-likelihood of every word/token that appeared in both pro- and anti- tweets at least 10 times, as a measure of how characteristic they were to one class as opposed to the other. . . a measure of the odds that our observation is due to chance rather than the true nature of [their] datasets.”
Using this result, Taylor et al. created word clouds of “the 40 words most characteristic of anti-feminist and pro-feminist tweets, respectively” and provide the following analysis: pro-feminist tweets (PF) are more likely to mention feminism and feminist as an adjective, while anti-feminist tweets (AF) tend to mention feminists as a group; PFs use first- and second-person pronouns, AFs use third-person pronouns; the groups use different linking words to define feminism; PFs link to external content, AFs link to local and self-created content; AFs use more punctuation; AFs tweet more about feminist history; PFs use more gender-related terms; AFs use more pejorative terms. While none of this can be absolutely definitive, and despite the caveats noted by the author, the analysis indicates interesting tendencies that could be good reference points for future research about online feminism-related discourse.
Discussion
Taylor et al.’s project and mine both operate with similar interests; applying quantitative methods to find qualitative tendencies in feminism-related discussion on Twitter. I do think of my data project as the preliminary process for a more comprehensive work. However, as I mentioned above, my articulation of the research question was not concrete enough even as I started exploring the collected data. Reading about Taylor et al.’s project was very helpful in articulating more concrete questions to explore. Some potential directions that my project could take in the future include:
- Examining the word choice of users that participated in the hashtag movement, as opposed to other users who have not
- Comparing the word choice of users that participated in the hashtag movement before and after they started using the hashtag
I could also model the project after Taylor et al.’s. However, I think that using the hashtag as an indicator of some sort will be a more interesting approach. The reason is that as I have closely observed my (Korean) Twitter timeline over the last two years, I witnessed a quite big change in the way feminism is discussed, both in terms of volume and of depth, at least within my social network bubble. Many offline activist movements were triggered by this hashtag; the hashtag was the first of its kind in Korean social networks. At the same time, I also felt a surge of backlashing adversarial discourse against feminism. I see a parallel between what has been happening in South Korea and what has been happening in the Anglophone social network space. Future work could contribute to ethnographic researches of online discourse in general, and also to document a digital (and perhaps intersectional) feminist politics.
Both approaches listed above will require more data collection (other tweets from the users than tweets with the hashtag), a close reading of the five thousand tweets with the hashtag (in order to better identify whether someone is genuinely participating in the movement), along with a quantitative analysis of the new collected data. I feel I am equipped for the first two elements, and ready to experiment with the latter.
References
Jang, Hayeon, Munhyong Kim, and Hyopil Shin. “KOSAC: A Full-fledged Korean Sentiment Analysis Corpus.” Sponsors: National Science Council, Executive Yuan, ROC Institute of Linguistics, Academia Sinica NCCU Office of Research and Development (2013): 366.
Eunjeong L. Park, Sungzoon Cho. “KoNLPy: Korean natural language processing in Python”, Proceedings of the 26th Annual Conference on Human & Cognitive Language Technology, Chuncheon, Korea, Oct 2014.
David Taylor, Zafarali Ahmed, Jerome Boisvert-Chouinard, Dave Gurnsey, Nancy Lin, and Reda Lotfi. “Most characteristic words in pro- and anti-feminist tweets.” 2015. http://www.prooffreader.com/2015/05/most-characteristic-words-in-pro-and.html
World Economic Forum. Global Gender Gap Report 2015. http://reports.weforum.org/global-gender-gap-report-2015/the-global-gender-gap-index-2015/